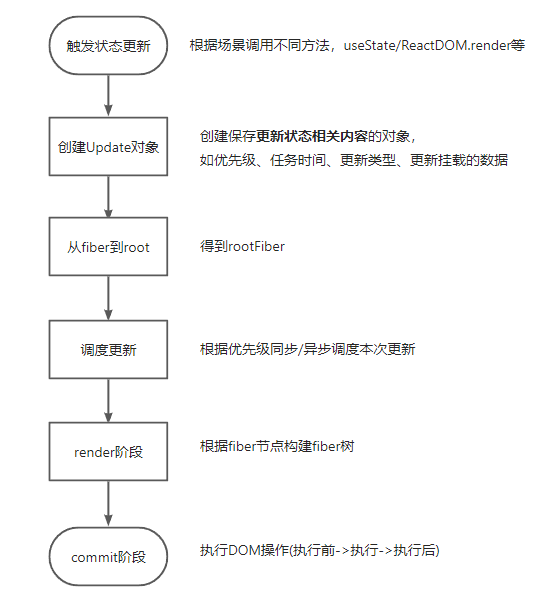
// react V < 18 functionscheduleUpdateOnFiber(fiber, lane, eventTime) { if (lane === SyncLane) { // 省略其他代码...
if (executionContext === noContext) { flushSyncCallbackQueue(); } } }
// 这里不用关心,只是单纯了解下18版本源码 // react V18 // flushSyncCallbacksOnlyInLegacyMode 命名更语义化了 functionscheduleUpdateOnFiber(fiber, lane, eventTime) { if ( lane === SyncLane && executionContext === NoContext && (fiber.mode & ConcurrentMode) === NoMode && // Treat `act` as if it's inside `batchedUpdates`, even in legacy mode. !ReactCurrentActQueue$1.isBatchingLegacy ) { // Flush the synchronous work now, unless we're already working or inside // a batch. This is intentionally inside scheduleUpdateOnFiber instead of // scheduleCallbackForFiber to preserve the ability to schedule a callback // without immediately flushing it. We only do this for user-initiated // updates, to preserve historical behavior of legacy mode. resetRenderTimer(); flushSyncCallbacksOnlyInLegacyMode(); } }