文件上传和下载是很常见的功能,今天就来梳理一下操作文件过程中常见的概念和 api,加深对文件的理解。
概念 Blob 对象 当用户通过一个input元素选择文件时,浏览器会创建一个Blob对象代表该文件的二进制数据。如果要在将文件数据上传到服务器或者存储到本地之前对其进行操作,你可能需要使用 Blob对象 。
举个例子,你可以使用URL.createObjectURL方法创建一个URL代表这个Blob对象,然后用这个URL在<img>或video元素中展示这个文件。如:
1 2 const img = document .createElement ('img' );img.src = URL .createObjectURL (file);
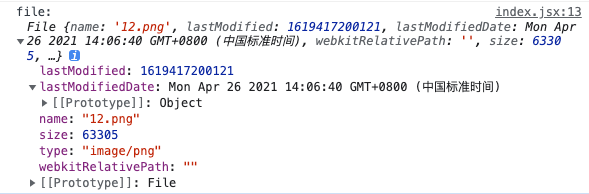
File 对象 当用户通过一个input元素选择文件时,浏览器会创建一个基于Blob对象的File对象,并添加文件名name、大小size、上次修改日期lastModifiedData等属性。如果要在将文件上传到服务器之前验证文件的属性,则可能需要使用File对象。
:::info
base 64 base64 编码将二进制数据表示为一串 ASCII 字符「我们常说的字符串」。
比如,一个传输协议是基于 ASCII 文本的,那么他就不能传输二进制流,想要传输该二进制流就得编码。常用的 http 协议的 url 就是纯文本的,不能直接放二进制流。
举个例子,你可以使用FileReader.readAsDataURL()方法读取 File 对象的内容并将其转换为 base64 编码的 data:URL 格式的字符串,简称DataURL。二进制数据并将其保存为文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 export const fileByBase64 = (file, callback ) => { var reader = new FileReader (); reader.onload = function (e ) { console .log (e.target .result ); callback && callback (e.target .result ); }; reader.readAsDataURL (file); };
简单的文件上传 文件上传的传统形式,是使用type='file'的input表单元素
1 <input type ="file" id ="file-input" accept =".jpg, .jpeg, .png" multiple />
可以添加change事件监听读取文件对象列表event.target.files:
1 2 3 4 const fileInput = document .getElementById ('file-input' );fileInput.addEventListener ('change' , (e ) => { const files = e.target .files ; });
File 对象:
文件上传前,可以通过File对象,验证文件大小、类型等信息,决定是否进行下一步,比如验证文件大小。
验证文件大小 1 2 <input type ="file" id ="file-input" /> <button id ="upload-btn" > Upload File</button >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 const fileInput = document .getElementById ('file-input' );const uploadBtn = document .getElementById ('upload-btn' );uploadBtn.addEventListener ('click' , () => { const selectedFile = fileInput.files [0 ]; const fileSizeLimit = 5 * 1024 ; if (selectedFile.size > fileSizeLimit) { alert ( 'Selected file exceeds the size limit of 5 KB. Please select a smaller file.' , ); return ; } });
1 2 3 4 5 6 获取 files 的方式: - 在 input 元素的 change 事件中,可通过 e.target .files 获取; - 或者通过 input 元素直接获取,如:document .getElementById ('file-input' ).files ; 也就是说`e.target === fileEl`
显示读取进度(下载文件的场景) FileReader.onprogress pregress事件,在读取Blob时触发。在下载文件并显示进度这个场景下能够派上用场。
1 2 3 4 5 6 <input type ="file" id ="file-input" /> <div > <label id ="progress-label" for ="progress" > Upload File</label > <progress id ="progress" value ="0" max ="100" value ="0" > 0</progress > <button id ="read-blob" > 读取Blob</button > </div >
readAsDataURL能够读取Blob对象,然后监听FileReader的progress事件,通过ProgressEvent.loaded和ProgressEvent.total计算读取的进度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 const fileInput = document .getElementById ('file-input' );const readBlobBtn = document .getElementById ('read-blob' );const reader = new FileReader ();reader.addEventListener ('progress' , (e ) => { if (e.loaded && e.total ) { const percent = (e.loaded / e.total ) * 100 ; progress.value = percent; } }); readBlobBtn.addEventListener ('click' , () => { const selectedFile = fileInput.files [0 ]; reader.readAsDataURL (selectedFile); });
显示上传进度 要显示文件的上传进度,可以使用 JavaScript 中的 XMLHttpRequest (XHR) 对象将文件上传到服务器并使用 XMLHttpRequest.upload.onprogress 事件跟踪进度。这是一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 const fileInput = document .getElementById ('file-input' );const uploadBtn = document .getElementById ('upload-btn' );const uploadProgress = document .getElementById ('upload-progress' );uploadBtn.addEventListener ('click' , () => { const selectedFile = fileInput.files [0 ]; const xhr = new XMLHttpRequest (); xhr.open ('POST' , '/upload' ); xhr.upload .onprogress = (event ) => { const progress = (event.loaded / event.total ) * 100 ; uploadProgress.value = progress; }; xhr.onload = () => { console .log ('File uploaded successfully' ); }; xhr.onerror = () => { console .log ('File upload failed' ); }; const formData = new FormData (); formData.append ('file' , selectedFile); xhr.send (formData); });
上传目录 input元素的webkitdirectory属性,表示允许用户选择文件目录,而不是文件。
1 <input type ="file" id ="file-input" webkitdirectory />
选择目录时,该目录下的文件会全部选中(包括子孙文件)。
拖放上传 设置一个放置文件的目标元素。
1 <div id ="drop-zone" > Drop files here</div >
调用 event.preventDefault(),这使它能够接收 drop 事件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 const dropZone = document .getElementById ('drop-zone' );dropZone.addEventListener ('dragover' , (event ) => { event.preventDefault (); dropZone.classList .add ('drag-over' ); }); dropZone.addEventListener ('dragleave' , (event ) => { event.preventDefault (); dropZone.classList .remove ('drag-over' ); }); dropZone.addEventListener ('drop' , (event ) => { event.preventDefault (); dropZone.classList .remove ('drag-over' ); const files = event.dataTransfer .files ; console .log ('files: ' , files); const xhr = new XMLHttpRequest (); xhr.open ('POST' , '/upload' ); xhr.onload = () => { console .log ('File uploaded successfully' ); }; xhr.onerror = () => { console .log ('File upload failed' ); }; const formData = new FormData (); formData.append ('file' , files[0 ]); xhr.send (formData); });
Content-Type(表单的 enctype 属性) 当 method 属性值为 post 时,enctype 就是将表单的内容提交给服务器的数据编码类型。可能的取值有:
application/x-www-form-urlencoded:未指定属性时的默认值。
multipart/form-data:当表单包含 type=file input 元素时使用此值 。
text/plain:出现于 HTML5,用于调试。这个值可被 <button>、<input type="submit"> 或 <input type="image"> 元素上的 formenctype 属性覆盖。
这种数据编码类型只支持传输文本数据
1 2 3 4 POST http://www.example.com HTTP/1.1 Content-Type: application/x-www-form-urlencoded;charset=utf-8 title=test&sub%5B%5D=1&sub%5B%5D=2&sub%5B%5D=3
首先,Content-Type 被指定为 application/x-www-form-urlencoded;其次,提交的数据按照 key1=val1&key2=val2 的方式进行编码,key 和 val 都进行了 URL 转码。大部分服务端语言都对这种方式有很好的支持。
此类型不适合用于传输大型二进制数据或者包含非 ASCII 字符的数据。平常我们使用这个类型都是把表单数据使用 url 编码后传送给后端,二进制文件当然没办法一起编码进去了。所以 multipart/form-data 就诞生了。
为了支持文件上传,表单数据必须使用multipart/form-data内容类型进行编码。这种编码格式允许二进制数据作为请求主体的一部分发送。
1 2 3 4 5 6 7 8 9 10 11 12 13 POST http://www.example.com HTTP/1.1 Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryrGKCBY7qhFd3TrwA ------WebKitFormBoundaryrGKCBY7qhFd3TrwA Content-Disposition: form-data; name="text" title ------WebKitFormBoundaryrGKCBY7qhFd3TrwA Content-Disposition: form-data; name="file"; filename="chrome.png" Content-Type: image/png PNG ... content of chrome.png ... ------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
Content-Type被指定为multipart/form-data,boundary为----WebKitFormBoundaryrGKCBY7qhFd3TrwA。boundary用于分割提交的数据。Content-Disposition包含文件的基本信息,Content-Type表示文件内容类型。text的表单字段,该字段的内容是字符串title。第二部分是名为file的字段,文件名为chrome.png,文件内容类型为image/png,内容为PNG ... content of chrome.png ...,然后以boundary为结尾。
这是一个传统的最简单的 form 表单上传如下:
1 2 3 4 5 <form method ="POST" enctype ="multipart/form-data" > <input type ="file" name ="file" value ="请选择文件" /> <input type ="submit" /> </form >
FormData 的由来: enctype="multipart/form-data",会导致后端在解析 Form 表单的数据格式时与 Ajax 上传的数据格式不一致的问题。为了后端能够使用相同的代码解析这两种提交方式,所以出现了FormData。
FormData 接口提供了一种表示表单数据的键值对key/value的构造方式,可以轻松的将数据通过 Ajax 发送出去。
1 2 3 4 5 6 7 8 9 const formData = new FormData ();formData.append ('files' , file); _files.forEach ((file ) => { formData.append ('files' , file); });
使用 FormData 上传文件时,无需手动设置Content-Type='multipart/form-data',FormData 会自动设置正确的 Content-Type 和 数据类型。
实际开发过程中也是如此,通常会使用 FormData 格式保存文件,关于Content-Type需要什么类型,取决于后端是怎么设计的。
下载 window.open open()方法,用于将指定的资源加载到浏览器新的窗口或者标签页。
1 2 3 const imgUrl = 'https://nd-news-mangement.oss-cn-hangzhou.aliyuncs.com/2023/04/274a8263e05f37a5d8663193b86e1a0583.png' ; window .open (imgUrl);
location.href location.href表示将当前页面的 URL 设置为一个新的值。它是一个字符串,包含当前页面的完成 URL,包括协议、域名、路径、查询参数和片段标识符。
1 2 3 const imgUrl = 'https://nd-news-mangement.oss-cn-hangzhou.aliyuncs.com/2023/04/274a8263e05f37a5d8663193b86e1a0583.png' ; location.href = imgUrl;
window.open和location.href的区别:
window.open会打开一个新窗口或选项卡,而location.href会替换当前页window.open 打开太多新窗口可能会对用户体验产生负面影响location.href可能会刷新整个页面(但如果在输入框中输入了文本,加载新页面时文本内容不会丢失,这是因为浏览器通常将表单数据保存在浏览器的缓存中)
a 标签 a 标签通常用于用户启动的交互,而location.href通常用于响应用户事件。download、target,也更为灵活,在实际开发过程中,我们通常会使用 a 标签封装一个下载功能的函数来使用,如下:
1 2 3 4 5 6 7 8 9 10 11 function downloadFile (url, fileName ) { const link = document .createElement ('a' ); link.href = url; link.target = '_blank' ; link.download = fileName; link.style .display = 'none' ; document .body .appendChild (link); link.click (); document .body .removeChild (link); }
总结
File 对象是基于 Blob 对象的,只不过多了一些附加信息,如 name、size等
想要显示文件读取进度时,我们可以通过 FileReader 的 readAsDataURL(file) 方法,然后监听FileReader的progress事件
想要显示上传到服务器的进度时,可以通过xhr.upload.onprogress事件
使用 FormData 上传文件时,无需手动设置Content-Type='multipart/form-data',FormData 会自动设置正确的 Content-Type 和 数据类型
实际项目应用中,大多数的表单场景都是手动上传文件到服务器,也就是说在提交到服务器之前,我们是不需要使用后端接口的。但现实中遇到的情况往往是后端提供一个上传接口,再提供一个提交表单数据的接口,前一个接口就显得很多余,而且存在数据库内存被乱用的风险。
参考: