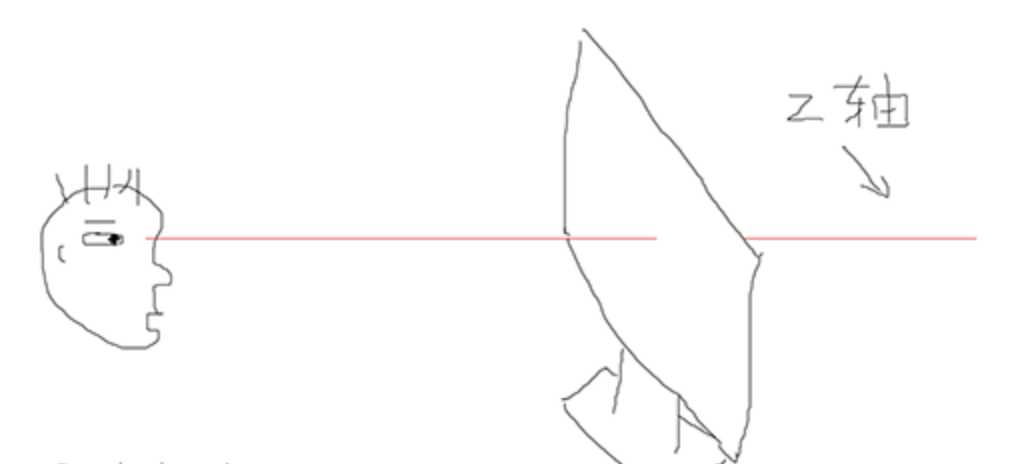
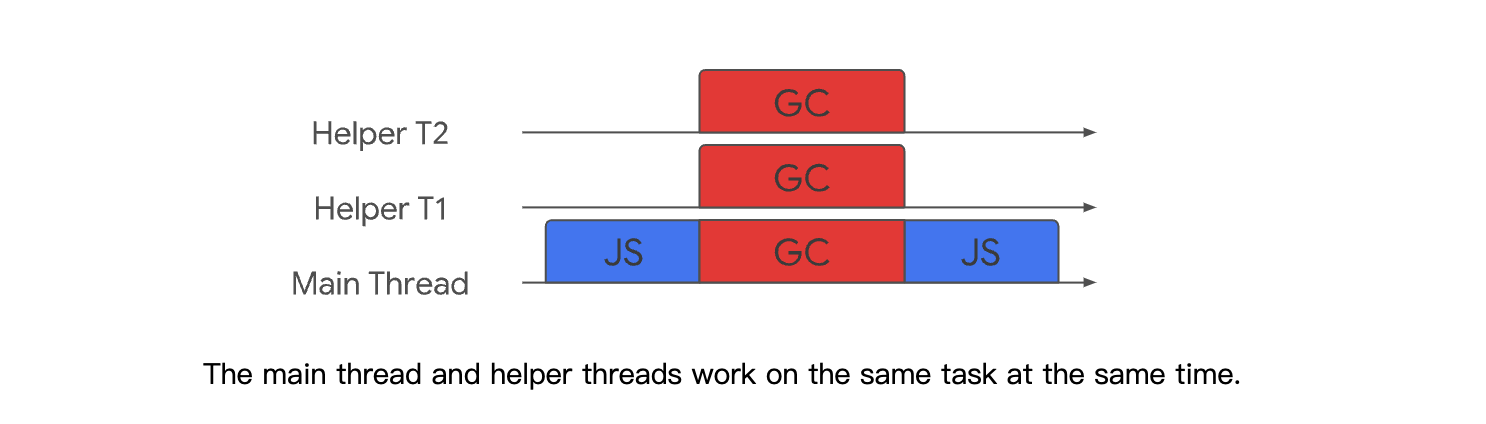
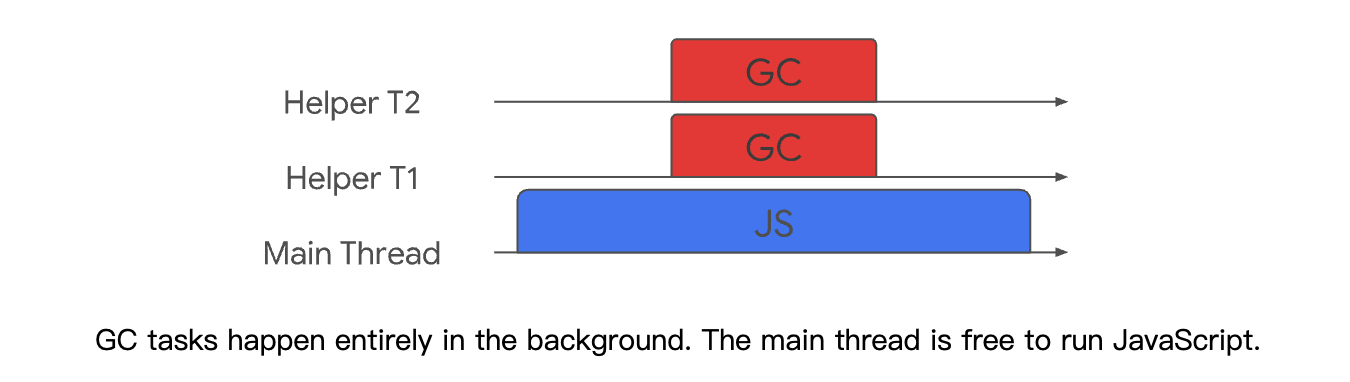
同步于异步
同步:按函数调用栈执行
异步:分发器分发一个任务,被通知后执行
定义
负责 JS 执行环境的代码执行顺序的问题。如果没有异步事件,函数调用栈几乎可以解决所有执行顺序问题。而事件循环机制,就是异步事件代码执行顺序的解决方案。
那么,浏览器中有哪些异步事件,以及它们各自有哪些特点呢?
线程
许多异步事件,都是由线程负责处理。
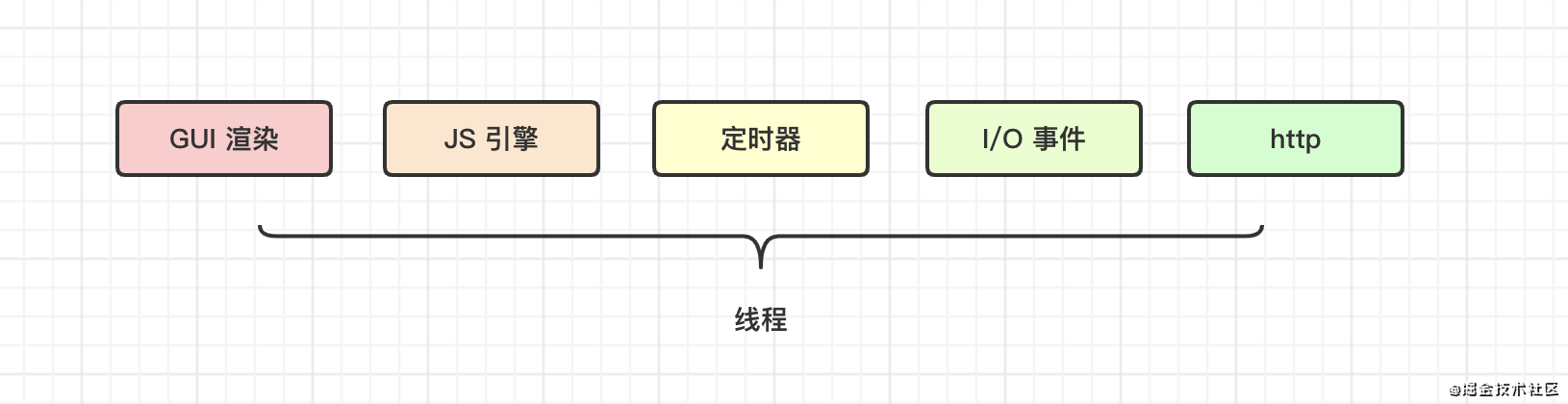
JS 是单线程的,但是 JS 的执行环境是由多个线程协同工作的。不同的线程,对应着不同的异步事件。
五个线程
GUI 线程
负责 HTML 的解析与渲染。DOM 结构的修改是同步的,但是 DOM 的渲染过程是异步的。
JS 引擎线程
负责 JS 代码的运行。
每一个网页,只会启动一个 JS 线程来配合完成页面的交互。
定时器线程
专门负责 setTimeout/setInterval 的逻辑。
回调函数中的逻辑并不会马上执行,即使将时间设置为 0,这也是异步的。
I/O 时间触发线程
当我们鼠标点击与滑动、键盘的输入等都会触发一些事件,而这些事件的触发逻辑的处理,就是依靠事件触发线程来帮助浏览器完成。
该线程也会把事件的逻辑放入队列中,等待 JS 引擎的处理。
http 线程
使用无状态短链接的 http 请求,在应用层基于 http 协议的基础之上,达到与服务端进行通信的目的。
该线程的触发逻辑,不是在 JS 引擎线程中,这个过程是异步的。
小结:除了 JS 引擎线程,其他四个线程分别处理与之对应的异步任务。比如定时器线程,由任务分发器 setTimeout /setInterval 分发异步任务进入定时器执行队列。
与 UI render 紧密相关的 raf/ric
requestAnimationFrame 简称「raf」,它是动画的重要实现手段。他跟前面介绍的异步方式大有不同,跟 UI render 紧密相关。
结合浏览器的渲染机制共同理解。
常规的显示器的刷新率为 60 Hz,也就是说,1 秒钟把页面刷新了 60 次,是最合理的频率。
这也是浏览器在进行 UI render 的合理频率。因此,每一次的渲染时间,控制在 1000 / 60 ms 以内。对浏览器来说才不会负荷工作。
requestAnimationFrame 是完成符合浏览器刷新频率的回调方式。
1
2
3
4
5
6
| 如果单次执行时间大于 16.67ms,也就是刷新率低于 60 Hz,会表现出卡顿;
卡顿的理解:
网络直播时,如果网络不好,会丢包导致卡帧。也就是说,下一秒的包还没发给你,自动刷新,刷新的还是上一次的老包,所以表现为卡顿,看起来就像刷新率低一样。
会用掉帧策略(放弃某一帧的任务)来解决。而不使用任务堆积。
|
1
| 如果高于 60hz,浏览器会超负荷工作。raf 的回调函数为 1000 / 60 执行一次,刚刚好符合浏览器刷新频率
|
我们通常喜欢将一次 UI render 描述为 一帧 「frame」。requsetAnimationFrame 只会在每一帧开始渲染之前执行。
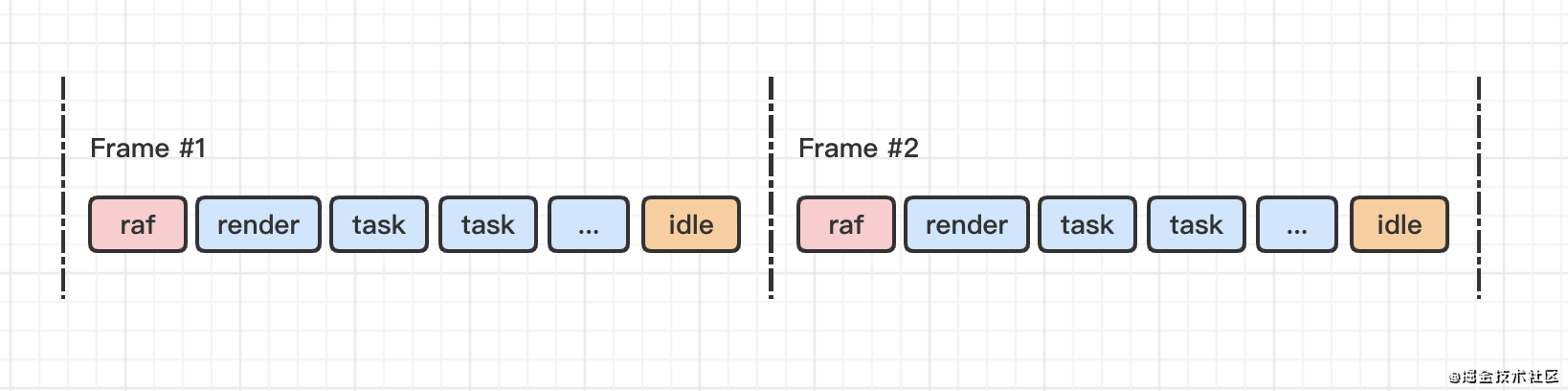
requestIdleCallback 简称「ric」,图中的idle,通常将优先级不高的任务放在 ric 中执行。
它的执行频率也跟 UI render 的频率一样。但是它会在每一帧的最后执行。
Promise
在浏览器中,线程对应的事件,并不能覆盖所有的异步事件类型。Promise 就是一个特例。
Promise 是 JS 的内部逻辑。并非由浏览器额外的线程来处理。因此,Promise 的异步逻辑与线程对应的异步逻辑是不一样的。
在 JS 引擎的处理逻辑中,Promise 有自己的事件队列,并且该队列在所有 JS 代码执行完成后执行。
1
2
3
| const p = new Promise((resolve, reject) => {});
p.then(f, r);
|
job
then 中的回调函数,就是一个 job。此处为 f 与 r。catch 同理。
PromiseJobs 执行队列
用于存储 Promise 异步逻辑。该队列在所有 JS 代码执行完之后执行。也可以说在 call stach 清空之后执行。
状态
一个 promise 有三种状态
- pending: 等待结果状态
- fulfilled: 已出结果,结果符合预期完成状态
- rejected: 已出结果,结果未符合预期完成状态
当一个 promise 实例在创建时,处于 pending 状态。
当 resolve 函数调用时, padding -> fulfilled
当 reject 函数调动是, padding -> rejected
当 promise 有了状态,不再是 padding ,那么我们称该 promise 的状态被固定: settled
何时进入 PromiseJobs
调用 p.then(f, r)时,会将 f 放入 [[PromiseFulfillReactions]]队列尾部,将 r放入 [[PromiseRejectReactions]]队列尾部。
这两个队列,是临时中间队列(准确的说,应该叫临时存储地方,出队时是无序的)。该队列中的 job 只会移入到 PromiseJobs 队列中而不会有自己的执行过程。 PromiseJobs 才有执行 job 的逻辑。
当 resolve/reject函数调用时,promise 产生了结果。此时,根据不同的结果,p.then(f, r)将不同的 job 「f / r」加入到 PromiseJobs 队列中。
如果在创建时,就已经 settled ,那么 job 会直接进入 PromiseJobs 队列中。
1
2
3
| const p = new Promise((resolve, reject) => {
resolve();
});
|
链式调用时,后续的 then 如何将 job 加入到 PromiseJobs 队列,需要根据上一个 then 的返回结果来决定。
- 当不确定返回结果时,且 then 已调用,对应的 job 进入临时队列中。
- 确定了返回结果之后,才会将 job 移入到 PromiseJobs 队列中。
PromiseJobs 队列如何执行
先进入的先执行。但是有一点要注意,当 job 执行时,可能会产生新的 job 进入到该队列。因此 PromiseJobs 在执行过程中会动态变化。
PromiseJobs 的执行规则
- 当所有 JS 代码执行完毕,PromiseJobs 队列开始出队执行
- PromiseJobs 处于动态变化中,只有当 PromiseJobs 队列为空时,才会结束执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| const PromiseJobs = [];
PromiseJobs.push(job1);
PromiseJobs.push(job2);
PromiseJobs = [job1, job2];
let job;
while ((job = PromiseJobs.shift())) {
job();
}
|
通过两例子感受一下
例子一:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| const p1 = new Promise((resolve) => {
resolve();
})
.then(function f1() {
console.log(1);
const p2 = new Promise((resolve) => {
resolve();
})
.then(function f3() {
console.log(2);
})
.then(function f4() {
console.log(4);
});
})
.then(function f2() {
console.log(3);
});
console.log(0);
|
Promise 在创建时,直接调用了 resolve , Promise 有了结果,因此, f1 马上被加入 PromiseJobs 队列。f2 要等待 f1 的结果,所以只能被加入临时队列。
1
2
| PromiseJobs = [f1];
PromiseFulfillReactions = [f2];
|
输出 0, JS 所有代码执行结束, 开始执行 PromiseJobs 列队中的逻辑
** f1 出队执行**, 输出 1, 遇到一个新的 Promise 对象, 且直接调用了 resolve , f3 进入 PromiseJobs 队列,f4 需要等到 f3 的执行结果, 所以进入临时队列
1
2
| PromiseJobs = [f3];
PromiseFulfillReactions = [f2, f4];
|
f1 执行结束, 可以得知 f1 返回了 undefined, 等价于 resolve(undefined). f1 有了结果, 所以 f2 进入 PromiseJobs 队列.
1
2
| PromiseJobs = [f3, f2];
PromiseFulfillReactions = [f4];
|
又开始执行 PromiseJobs 中的任务。
f3 出队执行, 输出 2
f3 执行完毕, 返回 undefined, 因此 f4 进入 PromiseJobs 队列
1
2
| PromiseJobs = [f2, f4];
PromiseFulfillReactions = [];
|
开始执行 PromiseJobs 中的任务
依次执行 f2 f4, 没有产生新的 job, PromiseJobs 变为空, 当前循环结束。
例子二:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| new Promise((resolve) => {
resolve();
})
.then(function f1() {
new Promise((resolve) => {
resolve();
})
.then(function f3() {
console.log(1);
})
.then(function f4() {
console.log(2);
})
.then(function f5() {
console.log(3.1);
});
})
.then(function f2() {
console.log(1.1);
new Promise((resolve) => {
resolve();
})
.then(function f6() {
new Promise((resolve) => {
resolve();
})
.then(function f7() {
console.log(4);
})
.then(function f8() {
console.log(6);
});
})
.then(function f9() {
console.log(5);
});
})
.then(function f10() {
console.log(3);
});
console.log(0);
|
Promise 在创建时, 直接调用了 resolve, 所以 f1 进入 PromiseJobs 队列. PromiseJobs = [f1]
f2 需要等待 f1 的执行结果才能进入 PromiseJobs 队列中, f10 需要等待 f2, 所以 f2 f10 都进入临时队列. PromiseFulfillReactions = [f2, f10]
输出 0, js 所有代码执行结束. 开始执行 PromiseJobs 队列中的逻辑
f1 出队并执行, f1 执行过程中, 遇到了新的 Promise, 并直接调用了 resolve, 所以 f3 的状态直接被固定, 进入 PromiseJobs 队列. PromiseJobs = [f3]
f4 和 f5 需要等待 f3 的结果才能入 PromiseJobs 队列. 所以只能进入临时队列. PromiseFulfillReactions = [f2, f10, f4, f5]
f1 逻辑代码执行完毕, 相当于 resolve(undefined) , f2 进入 PromiseJobs 队列. PromiseJobs = [f3, f2], PromiseFulfillReactions = [f10, f4, f5]. 开始执行 PromiseJobs 队列中的逻辑
f3 出队并执行, 输出 1, 逻辑代码执行完毕, f3 返回 undefined, 因此 f4 进入 PromiseJobs 队列. PromiseJobs = [f2, f4], PromiseFulfillReactions = [f10, f5]. 开始执行 PromiseJobs 队列中的逻辑
f2 出队并执行, 输出 1.1, 遇到新的 Promise, 新的 Promise 直接调用了 resolve, f6 直接进入 PromiseJobs 队列. PromiseJobs = [f4, f6], f9 进入临时队列, PromiseFulfillReactions = [f10, f5, f9]
f2 代码执行完毕, 返回 undefined, f10 进入 PromiseJobs , PromiseJobs = [f4, f6, f10], PromiseFulfillReactions = [f5, f9]. 开始执行 PromiseJobs 队列中的逻辑
f4 出队并执行, 输入 2, 返回 undefined, f5 进入 PromiseJobs, PromiseJobs = [f6, f10, f5], PromiseFulfillReactions = [f9]. 开始执行 PromiseJobs 队列中的逻辑
f6 出队并执行, 遇到了新的 Promise, 新的 Promise 直接调用了 resolve, f7 进入 PromiseJobs 队列, PromiseJobs = [f10, f5, f7], f8 进入临时队列. PromiseFulfillReactions = [f9, f8].
f6 执行完毕, 返回 undefined, f9 进入 PromiseJobs . PromiseJobs = [f10, f5, f7, f9]. PromiseFulfillReactions = [f8]. 开始执行 PromiseJobs 队列中的逻辑
f10 出队并执行, 输出 3, PromiseJobs = [f5, f7, f9], PromiseFulfillReactions = [f8]. 开始执行 PromiseJobs 队列中的逻辑
f5 出队并执行, 输出 3.1, PromiseJobs = [f7, f9], PromiseFulfillReactions = [f8]. 开始执行 PromiseJobs 队列中的逻辑
f7 出队并执行, 输入 4, 返回了 undefined, f8 进入 PromiseJobs 队列. PromiseJobs = [f9, f8], PromiseFulfillReactions = []. 开始执行 PromiseJobs 队列中的逻辑
f9 出队并执行, 输出 5, PromiseJobs = [f8], PromiseFulfillReactions = [], 开始执行 PromiseJobs 队列中的逻辑
f8 出队并执行, 输出 6, PromiseJobs = [], PromiseFulfillReactions = []. 循环结束
内循环的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| const queue = [];
function rafx(cb) {
queue.push(cb);
}
rafx(() => {
console.log(0.1);
});
rafx(() => {
console.log(0.2);
rafx(() => {
console.log(0.21);
});
});
rafx(() => {
console.log(0.3);
});
rafx(() => {
console.log(0.4);
});
rafx(() => {
console.log(0.5);
});
let cb;
while ((cb = queue.shift())) {
cb();
}
|
queue 队列为空时,才结束执行。
事件循环到底是怎么回事
我们已经知道,单纯依靠 call stask 不能完全覆盖所有代码的执行逻辑,call stask 的代码执行顺序永远都是同步的逻辑。对于许多线程引发的异步逻辑,需要依靠队列机制。
每一个异步行为,都有对应的执行队列。
执行队列
会在一轮循环中,直接执行的队列。如 PromiseJobs 队列。
临时队列
不会马上执行,处于等待状态的队列。在 promise 中,有两个临时队列, PromiseFulfilledReactions 与 PromiseRejectedReactions 。在满足条件后,才会将该队列中的任务,移入到执行队列中。有的临时队列又被称为事件表 Event Table,或注册表。
关于临时队列的理解
通常,在代码中,setTimeout,事件 I/O,http 请求,都会通过回调的方式编写代码的执行逻辑。
例如
1
2
3
4
| function foo() {
}
d.onclick = foo;
|
foo 就是回调函数。函调函数里的逻辑不会马上执行,而是要等到条件满足之后才会执行。
执行队列有哪些
- scriptJobs:指的是 script 标签,更顶层的供任务,S 代码执行的起点
- rafs:requestAnimationFrame 对应的队列
- UI render:渲染 UI 的任务队列
- ric:requestIdleCallback 对应的队列
- event queue:I/O 事件列队
- timer queue:定时器队列,由 setTimeout/setInterval 分发
- http queue:http 队列
- PromiseJobs:Promise 队列,由 p.then 分发
宏任务队列与微任务队列
每个队列都有各自鲜明的特点,如果非要区分这些异步队列是宏任务队列还是微任务队列,那么,除了 PromiseJobs ,其它的都可以理解为宏任务队列。
一轮循环的起点
同一时间,不会存在两个任务同时执行的情况。
UI 渲染也是一个任务,也不会与其它任务同时执行。所以我们常说,UI 渲染与 JS 代码时互斥的关系。
- 我们知道,PromiseJobs 是内循环,所以永远不可能作为一轮循环的起点
- UI render 的渲染,由 GUI 线程执行。所以 UI render 队列也不会是一轮循环的起点。
UI render 队列,是纯粹的渲染任务队列。既然要渲染任务,那必须有分发任务的指令才知道如何渲染。发起一个 http 请求也算是一个指令。
除了 PromiseJobs 和 UI render,其他所有任务队列中的任务「称之为 task」,都有可能是一轮循环的起点。
一轮循环完毕的标志
当次循环所有的执行队列都清空之后,一轮循环完毕。一轮循环完毕的标志是最后一个 task 中的内循环 PromiseJobs 队列清空。
事件循环的顺序
从 script 开始第一次循环
- 所有能作为起点的队列中的任务,都是进入主线程执行,借助函数调用栈依次执行,等调用栈清空,并且 PromiseJobs 为空,当次任务结束。PromiseJobs 是 task 的内循环
- 当次任务执行过程中,可能会产生新的任务,这些任务会放入临时队列或者下一次循环(比如定时器任务)的执行队列,当次循环的执行队列是执行一个少一个,直到清空为止。
- 任务分发时,多半都是进入临时队列,满足条件后,进入执行队列。
- 下一轮循环从执行队列中的第一个任务开始执行,直到当次执行队列清空为止
- 多个执行队列之间存在先后关系。raf -> ui render -> [event,http,timer] -> ric
- raf | ui render | ric 三个队列中的 task 不会每次循环都执行,他们的执行频率要和刷新率保持一致。因此多次循环中,他们都不会执行「执行队列为空」
任务进入执行队列的时机
以 setTimeout 为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| document.onclick = () => {
console.log('s');
setTimeout(() => {
console.log(0);
}, 0);
setTimeout(() => {
console.log(1);
}, 1000);
setTimeout(() => {
console.log(2);
}, 2000);
for (var i = 0; i < 5000000000; i++);
console.log('e');
};
|
分析一下
setTimeout 执行时,三个 task 进入了临时队列。
但是 for 循环的执行时间非常长,超过了 3 秒,因此,在 for 循环执行的过程当中,定时器线程发现 timer 临时队列中的任务满足了条件,就之间放入到了 timer 执行队列。
等 for 循环结束时,就依次快速输出 e 1 2 3。
再说 setInterval
1
2
3
| setInterval(function f1() {
func();
}, 100);
|
当 f1 的执行之间,会将 f1 放入临时队列。然后每隔 100 ms,会将 f1 这个任务重复的放入执行队列中。
这时候会有个问题,如果任务 f1 的执行时间超过 100 ms, 那么一轮循环里,执行队列里必然会多出一个 f1 任务,这就会让本次循环的时间拉长,后面队列的任务就会等待更多时间。
所以在 chrome 中,为了弱化这种情况的影响,timer 队列往往放在最后执行「仅比 ric 早」。
也正是这个原因,我们应该避免使用 setInterval, 不合理的使用可能会造成页面的严重卡顿。
所以我们常常使用 setTimeout 的递归调用方式来取代 setInterval .
1
2
3
4
5
6
7
| function fn() {
console.log(2);
setTimeout(fn, 100);
}
fn();
|
这种递归的方式,每次在 fn 执行完之后,才会 push 一个任务到临时队列中。然后临时队列满足 100 ms 的时间之后推入执行队列。也就是说,执行队列中的任务始终只会有一个,即使 fn 的执行时间超过了 100 ms,那它的影响也仅此而已,不会像 setInterval 那样累加。
举个例子
最有,再通过一个例子分析下事件循环的执行顺序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| setTimeout(function s1() {
console.log(5);
}, 1);
setTimeout(function s2() {
console.log(6);
}, 0);
new Promise(function (resolve) {
console.log(1);
for (var i = 0; i < 1000; i++) {
i == 99 && resolve();
}
console.log(2);
}).then(function p1() {
console.log(4);
});
console.log(3);
|
事件循环从 script 开始, 在主线程, 此时只有 scriptJobs 队列中有任务
遇到第一个 setTimeout 函数, setTimeout 进入函数调用栈, setTimeout 分发一个 task s1 进入临时队列, 但是因为 1ms 时间太短, 因此 s1 直接进入 timer 执行队列, timer = [s1], setTimeout 出栈
我们可能决定不立刻执行一个函数,而是在某时间之后执行,一般我们成为“调度执行”
因为调度的执行时间太短了,只有 1ms , 因此会立刻进入到执行队列。如果改成 2ms ,就可能不会这么快,就会先进入临时队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| setTimeout(function s1() {
console.log(5);
}, 1);
setTimeout(function s2() {
console.log(6);
}, 0);
setTimeout(function s1() {
console.log(5);
}, 2);
setTimeout(function s2() {
console.log(6);
}, 0);
|
又遇到 setTimeout, setTimeout 进入函数调用栈执行, setTimeout 分发一个 task s2, 因为延迟时间为 0, s2 直接进入 timer 执行队列队列, timer = [s1, s2] setTimeout 出栈
接下来遇到 Promise 的创建, Promise 构造函数进入函数调用栈, Promise 的第一个参数我们称为 executor, executor 会在 Promise 内部直接执行, 所以 executor 进栈,
又遇到 log 函数, log 进栈,输出 1, log 出栈. 在 for 循环时 遇到了 resolve 函数, resolve 进栈执行, Promise 状态被固定. log 进栈, 输出 2, log 出栈, resolve 出栈, executor 出栈, Promise 出栈
Promise 执行完, 接着执行 then 方法, 因此 then 进栈. then 方法时 Promise 的异步分发器. 本来 p1 应该直接进入 Promise 的临时队列, 但是 resolve 已经直接执行过了, 状态被固定, 因此已经知道了该如何执行, 所以 p1 直接进入 PromiseJobs 执行队列.
p1 进入执行队列后, then 执行完毕, 出栈.
然后遇到 log, log 进栈, 输出 3, log 出栈.
到这里, 主线程中的代码执行完毕, 调用栈也被清空了, 因此接下来就要执行 PromiseJobs 内循环. 发现 PromiseJos 队列中有任务, 开始执行 PromiseJobs 队列中的逻辑
p1 出队, 进入调用栈, p1 开始执行, log 进栈, 输出 4, log 出栈. p1 逻辑执行完毕, 出栈. 至此, PromiseJobs 执行队列已经清空, 内循环执行完毕. 当轮产生的 setTimeout 的任务, 应该放在下一轮执行. 至此第一轮循环结束
开始第二轮循环, 发现 timer 执行队列中有任务, s1 出队并进入函数调用栈, log 进栈, 输出 5, log 出栈, s1 出栈, timer = [s2]
s2 出队并进入函数调用栈, log 进栈, 输出 6, log 出栈, s2 出栈. s2 执行完之后, timer 队列也被清空了, 检查发现 PromiseJobs 队列中也没有任务, 所以可执行代码执行完毕, 循环结束
模拟一个没有临时队列的外循环事件分发器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
var tasks = [];
var addFn1 = function (task) {
tasks.push(task);
};
var flush = function () {
tasks.map(function (task) {
task();
});
};
setTimeout(function () {
flush();
});
addFn1(function add() {
console.log('my name is add fn');
});
addFn1(function foo() {
console.log('my name is foo fn');
});
|
也可以不利用事件循环,而是手动在适当的时机去执行对应的某一个方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
var tasks = [];
var addFn1 = function (task) {
tasks.push(task);
};
var dispatch = function (name) {
tasks.map(function (item) {
if (item.name === name) {
item.handle();
}
});
};
demoTask = {
name: 'demo',
handle: function () {
console.log('my name is demoTack');
},
};
addFn1(demoTask);
dispatch('demo');
|
于是,一个订阅-通知的设计模式就这样实现了。
思考
为什么要有一轮两轮
相当于给一个浏览器一个缓存的时间。告诉浏览器下一轮该执行什么,而不是打他个措手不及。如果没有异步任务,那其实一轮就够了。
再回到之前的例子
1
2
3
4
| function foo() {
}
d.onclick = foo;
|
从 script 标签开始第一轮循环,给 I/O 事件临时队列分发一个 task foo,主线程代码执行完毕,第一次循环结束。
当满足 onclick 条件时,foo 移入 I/O 事件队列, 并开始出队执行。