V8引擎如何工作的
v8 是谷歌开源的 JS 引擎,用于执行 JS 代码。清楚 JS 代码的执行顺序,有助于我们了解函数调用栈、事件循环等概念。
V8 的工作流程图
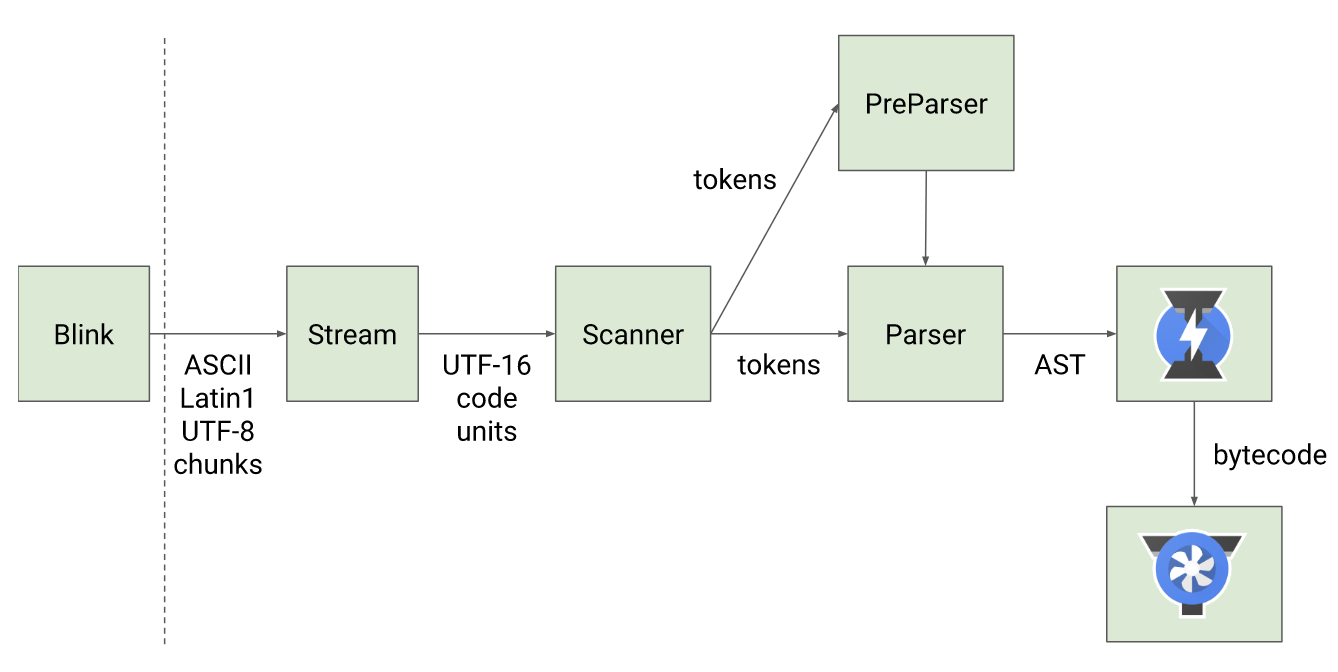
主要了解其中 4 个重要的概念
1.Scanner
scanner 表示扫描器,用于对纯文本 JS 代码进行词法分析。它会将代码分析为 tokens。tokens 表示不能再分割的最小单位,可能是单是字符,可能是一串字符串。
例如
1 | const a = 20; |
会被转为 token 集合,如下
1 | [ |
2.Parser
parser 表示解析器。解析过程是一个语法分析的过程,它会将 tokens 转换为抽象语法树「Abstract Syntax Tree」,同时验证语法,有问题就抛出错误。
继续上个例子,tokens 被解析为 AST 后的样子。
1 | { |
解析分为两种情况,预解析与全量解析。
预解析
在实际应用中,有大量代码,声明了函数,但未被执行。因此,如果全部都做全量解析的话,就会产生很多无用功。
预解析有以下特点
- 预解析会跳过未被使用的代码
- 不会生成 AST,会产生 scopes 信息
- 解析速度快
- 根据规范抛出特点的错误
1 | function foo1() { |
对于 foo1 来说,函数并没有声明,那么生成 ATS 并没有意义。所以 foo1 采用的就是预解析,可以观察到 foo1 函数作用域的信息已经生成了。也就是说,作用域的范围信息,在预解析阶段就已经确定了。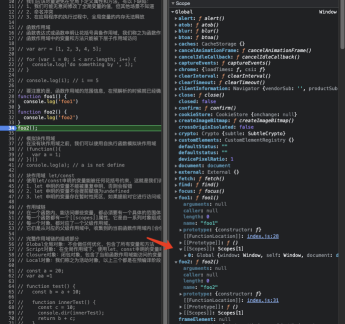
全量解析
全量解析会解析当前作用域的所有代码。会生成 AST,并且进一步明确更多的信息。
- 解析给使用的代码
- 生成 AST
- 构建具体的 scopes 信息,变量引用,声明等。
- 抛出所有的语法错误
需要区分的是,作用域和作用域链的信息在预解析阶段就确定了。
1 | // 声明时未调用,因此会被认为是不被执行的代码,进行预解析 |
3.Lgnition
Lgnition 是 V8 提供的一个解释器。它会将 AST 转为字节码「bytecode」。我们可以把这个过程理解为预编译。
4.TurboFan
TurboFan 是 V8 引擎的编译器模块。他会将 lgnition 收到的信息转为汇编代码。汇编语言可以理解为,表达了对寄存器的一个交互过程。
汇编代码就是对机器代码的封装,让人勉强能读懂。比如计算机一条加法指令为 10001010,汇编语言可用 add 表示。
汇编入门:
| 寄存器 | 概述 |
|---|---|
| eax | 累加器,可用于加减乘除等操作,使用频率高 |
1 | mov eax, 5; // 将数字5,传送到寄存器 eax 中 |
汇编就是使用约定好的指令,对寄存器进行各种操作。
lgnition + turboFan ,也就是「边解释边执行」。
5.Orinoco
Orinoco 是 V8 的垃圾回收器。
垃圾回收器会定期执行以下任务
- 标记活动对象和非活动对象「标记阶段」
- 回收/重用非活动对象所占用的空间「清理阶段」
- 整理内存「整理阶段」