内存与数据结构
把一个页面看做一个完整的独立应用。
那么,哪些个体参与了应用,个体以什么形式存在的,个体存放在哪里,个体在内存中如何存放?
个体 -> 数据类型 -> 内存 -> 数据结构
个体
个体可以理解为角色,这些角色会参与应用运行
有变量、函数、对象
1 | // 申明变量 |
a、add、M 表示个体的名字。我们可以通过名字,访问到具体的值。
数据类型
7 种基础数据类型和一种引用类型
基础数据类型
基础数据类型:Boolean、Null、Undefined、Number、String、BigInt、Symbol
重点理解 基础数据类型的值,是不可变的
1 | let a = 1; |
将 a 赋予 b,这时候 a 和 b 是等价的。随后 b++,b 的值被改变了,a 的值却没有改变。这意味着 a b 的等价,并不表示他们是同一个值。也就是说,a 赋予 b 的时候,重新给 b 分配了一块内存空间。因此我们说,基础数据类型,是按值访问的。用图表示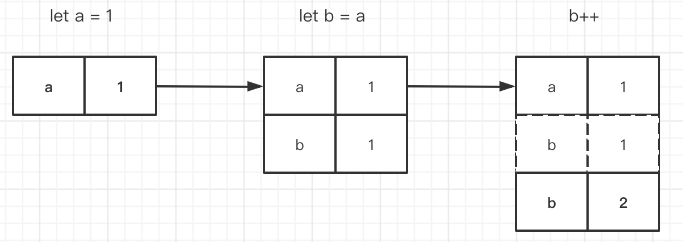
基础数据类型的比较,是值在比较
1 | const a = 1; |
当 a 和 b 在比较的时候,本质上是值在比较。
还有一点要注意,当我们使用字符串时,竟然可以使用方法,这是因为访问字符串时,实际上依然是在访问一个对象。使用字符串调用方法时,经历了以下 3 步骤
1 | // 首先使用包装对象创建对象 |
引用数据类型
与基础数据类型不同,引用类型的值是可以被改变的
1 | const book = { |
我们发现,修改变量 b2 的值,变量 book 也被修改了。这是因为执行 b2=book 时,b2 拷贝的是 book 的地址,所以他们指向的是同样的引用类型值。我们可称之为浅拷贝。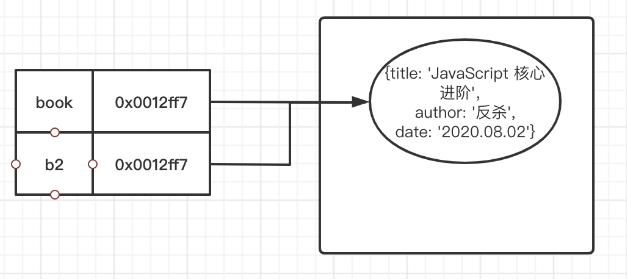
所以说,引用数据类型,是按引用访问的。这里的引用,指的就是内存中的地址。
地址:我们常说的地址,其实指的是内存中的首地址,因为一个引用对象占多少个内存格子是不确定的。内存管理器知道这个引用的大小,那么就能找到首尾地址。
引用类型的比较,本质上是他们的内存地址在比较。
1 | const a = { |
由于 c 和 d 是两个分开创建的对象,所以他们在内存中的地址是不一样的,所以结果也不同。直接比较引用地址,我们可以称之为浅比较。
还有一种场景,只比较一层数据结构,也被认为是浅比较,这种比较成本比较低,浅拷贝同理。
数据类型判断
判断是否为数组
- Array.isArray(arr)
- arr instanceof Array
- Object.prototype.toString.call(arr) === ‘[object, Array]’
判断是否为对象
- isObject
1 | function isObject(value) { |
- Object.prototype.toString.call(obj) === ‘[object Object]’
- obj instanceof Object 数组也成立
内存
运行一段 app/进程,操作系统会分配一段连续的内存空间,在内存中运行。
内存用于储存程序运行时的信息。CPU 通过寄存器直接访问,访问速度非常快。
硬盘可以将大量电影、图片等信息永久存储在硬盘。CPU 不能直接访问硬盘的数据,要通过硬盘控制器来访问。
我们可以将一些数据做持久化储存,也就是常说的本地缓存,其实就是将数据存储在硬盘。在浏览器中,提供了 localStorage 对象来帮助我们实现本地缓存。
内存和硬盘的区别:
| 对象 | 容量 | 访问速度 | CPU 能否直接访问 | 存储时效 |
|---|---|---|---|---|
| 内存 | 小 | 快 | 能 | 程序运行时 |
| 硬盘 | 大 | 慢 | 不能 | 持久性 |
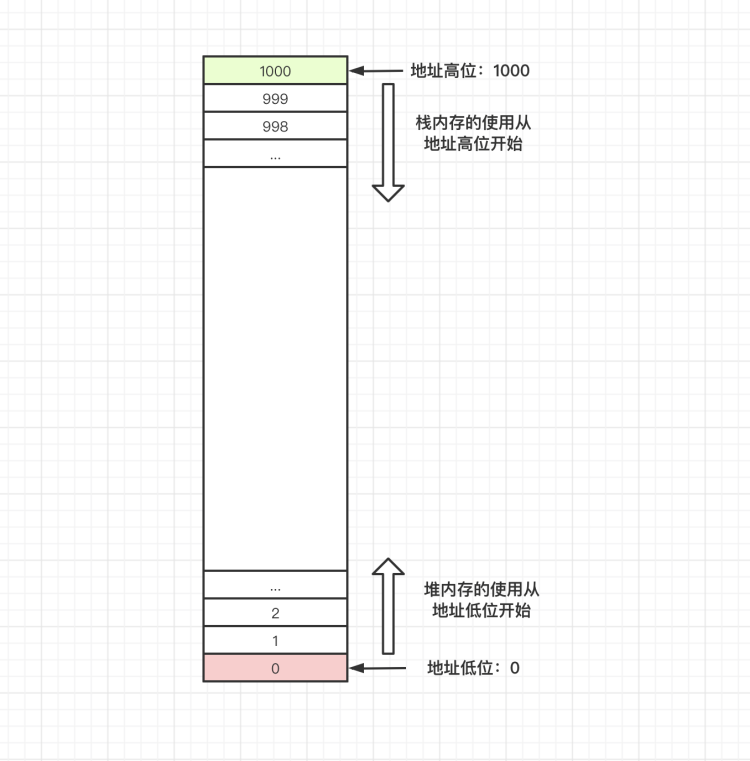
JS 中,内存分为栈内存和堆内存。栈内存与堆内存本身没有区别,只因为存取方式的差异,而有了不同。
使用栈内存时,从地址高位开始分配内存空间。使用堆内存时,从地址低位开始分配。
:::info
内存中的地址本应该用 16 进制表示,为了便于理解,此处用 10 进制表示。
:::
内存空间
Bit-比特
Byte-字节 计算机数据类型的最基本单位。1 Byte = 8 Bits
KB-千字节
MB-兆字节
GB-吉字节
TB-太字节
1 GM = 1024 MB
1 TB = 1024 GB
英文字母 占一个字节空间
中文汉字 占两个字节空间
英文标点符号 占一个字节空间
中文标点符号 占两个字节
指针、引用、对象
指针:也叫做首地址。指针占 4 个字节
0xFF
[1][2][3][4][][][][]
引用:指针的别名。在我们前端里,可以认为指针和引用是同个东西。
举个例子:
基础数据类型:
1 | var a = 10; |
0xFF(十六进制。我们这里用十进制代替,更直观)
[10][20][][][][][][]
改为 20 后,引用变量 a 的指针发生改变。10 失去了引用,等待被回收。所以我们说基础数据类型的值是不可变的。
0xFF
[10][20][][][]
引用数据类型:
1 | var b = 首地址 -> { m: 10 } |
首地址也是个基础数据类型。当我们改变引用类型时,首地址不变。
基础数据结构
基础数据结构主要介绍一下栈、堆、队列
栈
说到栈,其实有两种场景,栈数据结构和栈内存空间。
第一种场景,栈数据结构:表达的是对数据的一种存取方式。
把栈数据结构的存取方式,通过乒乓球盒子来分析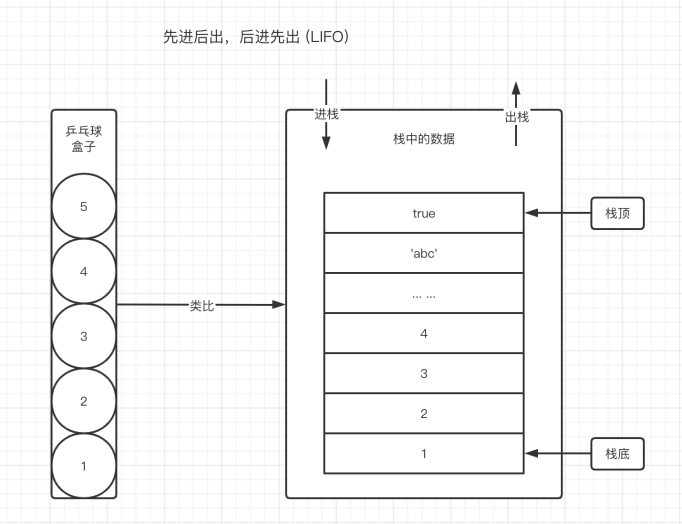
乒乓球依次入栈,5 号球位于最顶层,他一定是最后放进去的。1 号球位于最底层,你要想拿 1 号球,必须将上面所有乒乓球取出来之后才能取出。但 1 号球是最先放入盒子的。
这种存取方式与栈数据结构如出一辙。特点可以总结为先进后出,后进先出(LIFO Last in, First Out)。
javaScript 中,数组提供了两个栈方法来应对这种存取方式。
push:向数组末尾添加元素「进栈方法」
pop:删除数组末尾元素「出栈方法」
第二种场景,栈内存空间。刚刚提到,内存空间,因为操作方式不同才有了区别,而栈内存空间的操作方式,正是使用了栈数据结构的思维。
栈内存空间,用于记录函数的执行记录,管理函数的执行顺序。我们称他为函数调用栈「call stack」
应用场景:有效的括号、两个栈实现队列
堆
堆数据结构:是树结构中的一种。常见的是二叉堆。
二叉堆分为两种类型:最大堆和最小堆
最大堆:堆顶元素是整个堆中的最大值。任何父节点的键值都大于任何一个子节点
最下堆:堆顶元素是整个堆中的最小值。任何父节点的键值都小于任何一个子节点
以最小堆为例:
- 插入节点时,只能插入二叉堆的最后一个位置。比较节点时,如果插入节点比父节点大,则需要上浮,持续比较,直到比父节点小为止
- 删除节点时,我们通常只会删除堆顶的元素。删除后结构出现了混乱,需要将最后一个节点补充到堆顶。补充后树结构不符合最小堆的特性,因此需要与子元素进行比较,找到最小的子元素与其交换位置,这个行为称之为下沉。持续比较,知道符合最小堆的规则
应用场景:
数组的 sort 方法,也是采用类似堆的排序逻辑;前中后序遍历;
1 | function sort(a, b) { |
栈和堆的区别
- 分配方式不同:栈有操作系统分配;堆由开发人员分配
- 存放内容不同:栈用于存放函数的参数值、局部变量、函数返回值等;堆的存放内容由开发人员填充
- 释放方式不同:栈内存的数据,随生命周期函数的调用结束而结束。堆内存由开发人员释放,容易产生内存泄漏。
- 空间大小不同:每个进程拥有的栈大小远远小于堆大小。理论上,栈只有几兆大小,堆可以是虚拟内存的大小。
队列
先进先出的思维。在浏览器中,所有的异步事件都是放在任务队列中。
优先级队列是一个重要的概念,决定了哪个任务优先执行。
运用到实践中,有如下常用操作:
- 从队列最后入队
- 从队列头部出队
- 从队列任意位置离队(有其他事情)
- 从队列任意位置插队(特殊权利)
- 清空队列
应用场景:先到先处理
- 医院挂号
- promiseJobs
链表
链表是一种递归的数据结构,由多个节点组成,节点之前使用引用相互关联,组成一根链条。
链表的特征:
- 在内存中,链表是松散不连续的结构,通过引用确定节点之间的联系,不像数组那样是排列在一起的连续内存地址
- 链表没有序列,如果引用是单向的,只能通过上一个节点,找到下一个节点
- 节点之间的引用可以是单向的「单向链表」,也可以是双向的「双向链表」,还可以是首尾连接的「循环链表」
和数组的区别:
- 在内存空间里,链表是松散的,不连续的。数组是紧密的,连续的
- 在性能角度考虑,访问某个成员,数组远远优于链表,而新增/删除元素,链表远远优于数组
应用场景:
- 节点元素的相互引用,
nextSibling、previousSibling - 原型链中,由
__proto__进行关联的单向链表 - react 源码中的
Fiber节点中的nextEffect
内存空间管理
内存溢出:多指栈溢出
内存泄露:指某段内存空间无法被管理
- 没有引用,无法被访问
- 失去引用时,没被标记,无法被垃圾回收机制回收
思考
基础数据类型存在栈内存,引用数据类型存在堆内存,这句话对不对?
不对。栈内存和堆内存本身并没有区别,只是存取方式的差异而有了不同。基础数据类型可以在栈里,也可以在堆里,函数执行时的参数、变量都在栈里。引用类型的地址在栈里,引用类型的数据在堆里。
变量会存在内存中吗,如果存在,以什么方式存在
不存在。内存中只存在 16 进制的地址编码和具体的数值
m 的值是否被改变?为什么?
1 | const m = { |
m 被改变了。函数传入一个引用数据类型时,会干扰外部的值,参数变量的地址入栈内存,引用类型对象入堆内存。
为什么使用不可变数据类型:
因为浅比较无法比较出引用数据类型之间的差异
引用类型为什么有地址这个概念?
因为一个内存空间无法记录整个对象的值,所以用首地址(地址)来记录